Introduction to Understanding Emperical and Mathematical Analysis of Algorithms!!
Introduction
When doing time complexity analysis for any algorithm in hand, minimum care we should take is to do emperical analysis and mathematical analysis. I will talk little about both approaches plus and negatives of each and how using them both could help you getting better approximations.
Emperical analysis
Suppose you have problem of sorting n integers present in file and output new file with sorted integers. There are multiple ways to achieve the same task. So given any two appoaches to same problem, emperical analysis will deal with actually running them on target with different set of data and then measuring performance. This would definitely give you more visual insight about what is exactly happening.
Advantages of Emperical Analysis
You are definately getting some exact numbers to compare. You have to be more carefull while chosing the test input. It is adviced you seperate your input in three types.Normal input , Random input and Obfuscated input. Also generate large and random sample size so you hit close to the worst case.
It will take into account even constant factors contributing to final execution time which mathematical analysis might ignore.
Disadvantages of Emperical Analysis
Emperical analysis is tied very hard to architecture you are running on. It may be affected by the way you chose inputs or the two approaches you chose to solve problem may not be comparable in first place.
This approach coupled with profiling tools you can still get some better inputs.
Mathematical Analysis
When we have algorithm it is always desirable to get the approximation of its run time and space complexity for general sample size.So mathematical analysis tries to approximate steps in your algorithm.You abstract operations in your algorithm which might be contributing most to execution time.
Then treat you algorithm as some function F. For some input set you run the algorithm and plot this function. You plot graph of sample size against execution time and then get the gradient of this graph. What you get is growth rate of the function F which is our algorithm.
So when mathematically approximating runtime for F we can do that by finding some function G such that G also produces same growth rate. So if you plot graph of G it would be similar to F somewhat.
Formal Definition: f(n) = O(g(n)) means there are positive constants c and k, such that 0 ≤ f(n) ≤ cg(n) for all n ≥ k. The values of c and k must be fixed for the function f and must not depend on n.
Please see in following graph. The growth rate of function f(n) (n is number of input) below some number K is very non linear.Hence it is very hard to find function that would approximate f(n). After K the graph of f(n) somewhat goes linear and close to c(some constant) * g(n). Hence we can find another function g(n) which is approximating f(n). We chose this g(n) to be function whose execution time or growth rate we know.
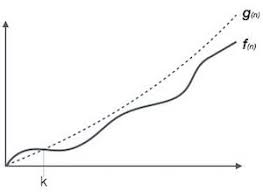
So in summary we abstracted our algorithm and identified the language contructs that might be contributing max to time complexity then treated it as function f(n) and then found approximation for it.
For most of the algorithms with polynomial time complexity generally induction and recurrence relation can be used to derive the approximation function g(n). But that is another topic.
Problems with Asymptotic Analysis :
If you see we are finding approximation so, If algorithm has time complexity of 3n + 4 generally we will say complexity is O(n) becuase t3n+4 is degree one polynomial. We do omit the constant term but for many sequential algorithms this constant term could be very large and might affect the final execution time.
Mathematical analysis is not much reliable when it comes to current multithreaded and multicore architectures as most of the execution will be dependent on how schedular schedules thread and how much stalling or thread throttling happens.Mathematical analysis do not consider this side effects of the system.
Another important aspect that is not considered in this analysis is cache performace or effect of cache coherency.So considering the ups and downs or both approach its always better to apply both to get better results.